Introduction
If you have been following Casper research, then you might have heard about the Casper CBC draft paper released at devcon4. If you have looked at the draft, you might have wondered how those esoteric math symbols are ever going to be put into simple words! This blog post aims to make the concepts in the draft more accessible.
This post will focus on simplifying the technical details of the draft. A good technical walk-through would be Barnabé Monnot’s explanation of the paper. Readers interested in knowing about the history of Casper are encouraged to read Vlad Zamfir’s blog posts on the same, and those interested in knowing about the Friendly Finality Gadget vs. Correct-By-Construction approach should check out Vitalik Buterin’s tweet storm covering this issue.
Over the years, many collaborators have contributed to the efforts to build a correct-by-construction consensus mechanism that would eventually be used for a full proof-of-stake blockchain (that perhaps would also support sharding) consensus algorithm. The current research team consists of Vlad Zamfir, Nate Rush, Aditya Asgaonkar, and Georgios Piliouras.

Casper CBC Design Philosophy
Correct-By-Construction
The fundamental design philosophy behind correct-by-construction protocols is to first build a very abstract but robust framework and provide proofs of fundamentally important properties that the framework guarantees. Then, we incrementally define the framework further, and inherit all past proofs and guarantees. Using this iterative approach of define-prove-inherit, we build families of protocols that satisfy the same proofs and provide the same guarantees at a high level, yet can be defined to be specialized enough for practical use.
It is called correct-by-construction because correctness of new protocols is guaranteed by their construction, which is by incrementally defining an abstract (and provably correct) protocol further.
Distributed Systems Approach
Casper CBC approaches the problem of proof-of-stake consensus as a distributed systems problem. Unlike other proof-of-stake consensus mechanisms, we do not define cryptoeconomic methods such as deposits and slashing conditions in our consensus mechanism! However, the protocol we define are general enough to define these things later on.
The concepts of faults in distributed systems is important to Casper CBC consensus. Section 1.1 of the draft describes a classification of various types of faults that may occur. The most interesting type of fault (and the only kind that can cause consensus safety failure) is called the equivocation fault. We will dig into this type of fault later, when we discuss the consensus rules.
The premise of the consensus mechanism is that “everything will be fine as long as there are only a sufficiently low number of faults”. This can be re-stated as “only if there are a sufficiently high number of faults will something go wrong”.
Casper CBC Consensus Mechanism
Let us get familiar with some terminology:
- Validators: The consensus forming peers nodes in the network are called validators.
- Messages: Messages are generated and passed around by validators in the effort of trying to reach consensus.
Messages
Messages are the pieces of information generated and passed around by validators while participating in the consensus forming process. In the Casper CBC consensus mechanism, messages have the following structure:
Message structure = (value, validator, justification)
Let us break down the message structure:
- Value: The value is the item that the validator proposes the network to come to consensus on. These values have to be from the set of consensus values. If we are building an integer consensus algorithm, then the consensus values will be integers. If we are building a blockchain consensus algorithm, then these consensus values will be blocks.
- Validator: This is the validator who is generating the message.
- Justification: The justification of a message is the set of messages that the validator has seen and acknowledged while generating that particular message. As we will see later, the justification is supposed to “justify” the proposed value.
Before we discuss rules that define restrictions on messages, let us look at two important concepts:
- Later Messages: If message A is in the justification of message B, then message B is later than message A.
- Estimator Function: The estimator function takes the justification (which is a set of messages) as input, and returns the set of consensus values that are “justified” by the input. For example, in an integer consensus setting, the estimator will return integer values. In a blockchain setting, the the estimator will return blocks which can be added on top of the current tip detected from the blocks in the messages in the inputted justification.
Consensus Rules
These rules classify two types of faults: the invalid message fault, and the equivocation fault.
- The proposed value must be in the set of consensus values returned by the application of the estimator function on the justification.
- The validator cannot make two messages with
- two different values, or
- two different justifications,
such that either message is not later than the other.
Violation of Consensus Rules
- Invalid Message Faults: The violation of the first rule results in the message being invalid, and can be detected by everyone who receives the message. The receiver runs the estimator function on the justification of the message, and checks whether the proposed value is in the set of values returned by the estimator. All messages which do not violate this rule are valid messages.
- Equivocation Faults: The violation of the second rule cannot be detected by anyone who receives only one of the two messages violating this rule. This violation is a type of Byzantine failure which we call equivocation. In the rest of this blog post, I will refer to the violation of this rule as faults.
When a node equivocates, it is basically executing multiple separate instances of the protocol, and may attempt to show messages from a single instance of these executions to separate peers in the network. To clarify what separate instances of the protocol are: consider a validator who violates consensus rule 2 by generating messages A and B that break the rule. The validator then starts maintaining two histories of protocol execution, one in which only message A is generated, and the other in which only message B is generated. In each single version of protocol execution, the validator has not equivocated.
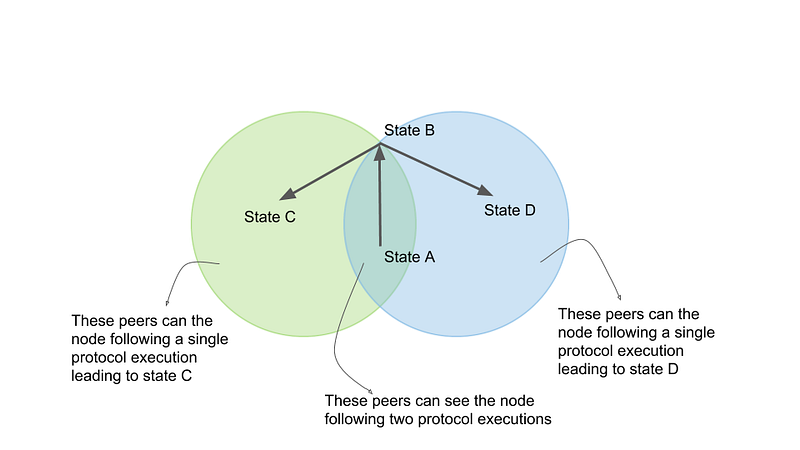
For example, in the illustration above, a node starts executing the protocol at state A, and continues a single protocol execution till state B. Peers in both the green (left) circle and blue (right) circle can see the node follow a single protocol execution from state A to state B, by observing the messages it sends. Then, the node starts maintaining two separate instances of protocol execution. It shows the peers in the green (left) circle the execution leading to state C, and shows peers in the blue (right) circle the execution leading to state D. Some of the peers (in the intersection) can see that the node is equivocating, and as the network gossips, more peers will find out about the node’s equivocating behavior. Consensus failure will be caused when a sufficiently large number of participants engage in this type of Byzantine behavior.
Decision Guarantee
The consensus rules guarantee (following a rigorous mathematical analysis) that after a sufficiently high number of validators have made valid messages that propose a given value, it is impossible to form consensus around a contradictory value without a large number of validators generating faults.
Therefore, a node “decides” on a consensus value (a.k.a. achieves finality on the value) after it has seen a sufficiently high number of validators propose the value in valid messages. This “sufficiently high” number depends on the fault tolerance threshold of that node. An important tool that allows nodes to detect final decisions is called the decision oracle.
Decision Oracle
The decision oracle is a tool for nodes to detect decisions on a particular consensus value based on the messages that they have seen. The basic idea behind detecting decisions is to find out if enough number of validators are agreeing with the consensus value in question, and if these validators see each other agreeing on the value.
This discussion is not included in the released draft yet, since we have yet to fix some details in our rigorous mathematical analysis of the decision oracle. We made significant progress on this (thanks to Greg Price) at a Stanford research workshop, and Nate Rush is currently putting in mammoth efforts into completing this!
Casper CBC — The Friendly GHOST
Following the Casper CBC methodology, let us define the protocol a bit more, and create a (GHOST-based)¹ blockchain consensus mechanism (Section 4.4 in the draft).
We need to define two things in the Casper CBC consensus mechanism to arrive at our destination (Definition 4.31):
- Consensus Values: We define the set of consensus values to be the set of all possible blocks.
- Estimator Function: We define the estimator to return all blocks which are equal to or descendants of the blocks returned by running the GHOST fork choice rule on the justification. (GHOST stands for Greedy Heaviest-Observed Sub-Tree, and is a way of selecting a canonical blockchain from a set of multiple blockchains. It can be thought of as a variant to the longest chain rule.)
Et voila! By defining the Casper CBC consensus mechanism a little bit more, we have a brand new blockchain consensus mechanism that has concrete decision safety guarantees, and we got the proof for free!
What next? Try making a consensus mechanism for sharded blockchains! (Section 4.6)